
AMPL - spreadsheet handling with amplxl#
![]()
![]()


![]()

Description: Basic example of reading/writing data into/from a .xlsx spreadsheet with amplxl
Tags: ampl, amplxl, spreadsheet, excel, xlsx
Notebook author: Nicolau Santos <nicolau@ampl.com>
# Install dependencies
%pip install -q amplpy
# Google Colab & Kaggle integration
from amplpy import AMPL, ampl_notebook
ampl = ampl_notebook(
modules=["highs", "plugins"], # modules to install
license_uuid="default", # license to use
) # instantiate AMPL object and register magics
amplxl#
amplxl is a table handler for spreadsheets in the .xlsx format. amplxl is available by default in most AMPL bundles. If it’s ot available in your AMPL install you canget it from the above link.
To load the library you need to add the instruction
load amplxl.dll;
in your AMPL file.
In this notebook we will take a quick look on how to use amplxl in the diet problem, available on Chapter 2 of the AMPL book.
%%writefile diet.mod
set NUTR;
set FOOD;
param cost {FOOD} > 0;
param f_min {FOOD} >= 0;
param f_max {j in FOOD} >= f_min[j];
param n_min {NUTR} >= 0;
param n_max {i in NUTR} >= n_min[i];
param amt {NUTR,FOOD} >= 0;
var Buy {j in FOOD} >= f_min[j], <= f_max[j];
minimize Total_Cost: sum {j in FOOD} cost[j] * Buy[j];
subject to Diet {i in NUTR}:
n_min[i] <= sum {j in FOOD} amt[i,j] * Buy[j] <= n_max[i];
Overwriting diet.mod
Sample data#
First we download a spreadsheet with the data for the diet problem from our github repository.
url = "https://raw.githubusercontent.com/ampl/colab.ampl.com/master/datasets/nfbvs/diet2D.xlsx"
import urllib.request
urllib.request.urlretrieve(url, "diet2D.xlsx")
('diet2D.xlsx', <http.client.HTTPMessage at 0x20439740950>)
When we open the spredsheet we have a sheet named nutr with the following information:
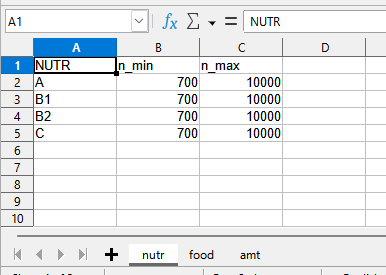
The table in this sheet contains the data for the indexing set NUTR and for the parameters n_mix and n_max, that are indexed by NUTR.
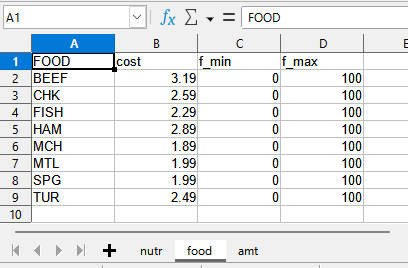
In the sheet food we have the data for the indexing set FOOD and for the associated parameters cost, f_min and f_max.
The sheet amt contains information for the amt parameter, that is indexed both by NUTR and FOOD.
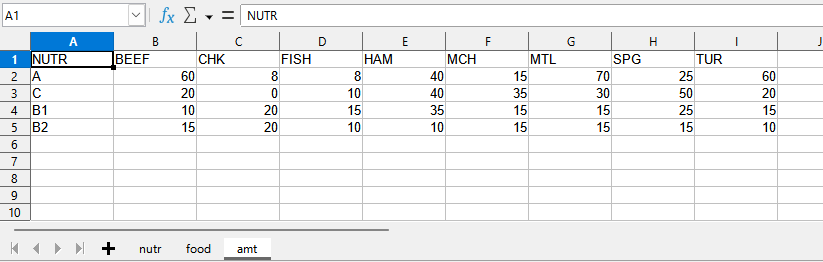
Note that the amt parameter is represented as a 2-dimentional table and the definition of FOOD is implicit.
Establishing connection#
Now we need to establish a connection between the data in the spreadsheet and AMPL. For each table in the spreadsheet we need a table declaration.
For the data in the nutr sheet the table declaration is the following:
table nutr IN "amplxl" "diet2D.xlsx":
NUTR <- [NUTR], n_min, n_max;
The declaration starts with the keyword table followed by the name of the sheet where the data is to be read from. IN indicates that we are reading data from the spreadsheet, "amplxl" is the name of the table handler and "diet.xlsx" is the path to the spreadsheet. The indexing sets in the table are enclosed between [ and ] symbols, followed by the associated parameters n_min and n_max. NUTR <- [NUTR] indicates that the data from the NUTR table in the spreadsheet is to be read into the NUTR set in AMPL.
The process is identical for the data in the food sheet
table food IN "amplxl" "diet2D.xlsx":
FOOD <- [FOOD], cost, f_min, f_max;
and similar to the data in the amt table
table amt IN "amplxl" "2D" "diet2D.xlsx":
[NUTR, FOOD], amt;
As amt is a 2-dimentional table, you need to specify the 2D keyword in the table declaration. The driver will detect the NUTR indexing set in the first column and assume that the elements in FOOD are the remaining elements of the first row.
Also note that you will need a table for each indexing set.
To load the data use the read command
read table nutr;
read table food;
read table amt;
Choose a solver and solve#
Now we are able to specify a solver and solve the model.
option solver highs;
solve;
We can wrap up all the statements in a single file “diet.run”.
%%writefile diet.run
reset;
load amplxl.dll;
model diet.mod;
table nutr IN "amplxl" "diet2D.xlsx":
NUTR <- [NUTR], n_min, n_max;
table food IN "amplxl" "diet2D.xlsx":
FOOD <- [FOOD], cost, f_min, f_max;
table amt IN "amplxl" "2D" "diet2D.xlsx":
[NUTR, FOOD], amt;
read table nutr;
read table food;
read table amt;
option solver highs;
solve;
Overwriting diet.run
and include the file with the following instruction
%%ampl_eval
include diet.run;
assert ampl.solve_result == "solved", ampl.solve_result
Report results#
It’s also possible to write the obtained results in an .xlsx spreadsheet.
As an example we will create a table with values associated with the Buy variable (lower bounds, values, upper bounds and reduced cost).
The syntax is very simillar to the read example above. The main differences are that we use OUT keyword, instead of the IN one, and that we change direction of the -> arrow.
table buy OUT "amplxl":
FOOD -> [FOOD], Buy.lb, Buy, Buy.ub, Buy.rc;
Afterwars the read instruction is replaced by a write one.
write table buy;
As no filename was specified the driver will create a file with the name of table and the .xlsx file extension, “buy.xlsx”, and write the table information into it.
%%ampl_eval
table buy OUT "amplxl":
FOOD -> [FOOD], Buy.lb, Buy, Buy.ub, Buy.rc;
write table buy;