Oil refinery production optimization (+PowerBI)#
![]()
![]()

Description: In this document, we present an enhanced approach to oil refining optimization by integrating Power BI for improved decision-making and data visualization. For a full description of the model, you can read more about it here.
This notebook showcases how Power BI, when combined with mathematical optimization, delivers powerful, actionable insights. By leveraging the dynamic reporting features of Power BI and the optimization capabilities of AMPL, users can interact with data in real-time and make well-informed decisions more effectively.
Tags: Oil production, Production optimization, Profitability, Refinery, mip, highs, powerbi, industry, scheduling, data-science, data-analysis, decision-making
Notebook author: Mikhail Riabtsev <mail@solverytic.com>
1. Introduction#
In this document, we present an enhanced approach to oil refining optimization by integrating Power BI for improved decision-making and data visualization. For a full description of the model, you can read more about it here.
This notebook showcases how Power BI, when combined with mathematical optimization, delivers powerful, actionable insights. By leveraging the dynamic reporting features of Power BI and the optimization capabilities of AMPL, users can interact with data in real-time and make well-informed decisions more effectively. This innovative method offers several key benefits:
Interactive Dashboards: Power BI’s user-friendly interface allows easy exploration of scenarios and results, without requiring advanced technical knowledge.
Real-time Data Integration: Dynamic data inputs ensure optimization is always based on the most current information, keeping decisions timely and relevant.
Scalability: Power BI’s ability to handle large datasets makes it ideal for implementing optimization models on a larger scale.
User-Friendly Reporting: Clear and intuitive visual representations of optimization results enhance understanding, facilitating smoother communication across teams. Together, AMPL and Power BI create a streamlined process, bridging the gap between model development and real-world decision-making.
1. Download Necessary Extensions and Libraries#
Ensure you have a registered Power BI Service account and uploaded Oil_refining.pbix file to your Power BI Service.
# Install dependencies
%pip install -q amplpy pandas powerbiclient
from powerbiclient import Report, models
from io import StringIO
import pandas as pd
# Google Colab & Kaggle integration
from amplpy import AMPL, ampl_notebook
ampl = ampl_notebook(
modules=["highs"], # modules to install
license_uuid="default", # license to use
) # instantiate AMPL object and register magics
3. Embed the Power BI Report with Data#
Integrate your Power BI report to Jupyter Notebook.
# Get the group and report ID from PowerBI service
group_id = "c498f9cc-fb27-4ba4-96b6-d4c1813624c2" # YOU HAVE TO PUT HERE YOUR POWER BI GROUP ID OR WORKSPACE ID
report_id = "7500c9bc-ac5e-4e91-a8ff-bba318f3d6a9" # YOU HAVE TO PUT HERE YOUR POWER BI REPORT ID
# Creating an instance of the Report class by passing group_id, report_id, and interactive_auth
report = Report(group_id=group_id, report_id=report_id, auth=device_auth)
# report.set_size(900, 1240) # This line is commented out but would set the size of the report's output.
report # Show the power BI report with data.
4. AMPL Model Formulation#
Define and set up the optimization model.
%%ampl_eval
reset;
### SETS
set CRUD ; # Types of crude oil (Crude1, Crude2)
set DIST ; # Distillation products
set REF ; # Reforming products
set CRACK ; # Cracking products
set LUBR ; # Lubricating products
set PROD ; # Final products
set STAT ; # Delivery stations
set D_MODE ; # Operating modes of the equipment of the Distillation installation
set R_MODE ; # Operating modes of the equipment of the Reforming installation
set CR_MODE ; # Operating modes of the equipment of the Cracking installation
set L_MODE ; # Operating modes of the equipment of the Lubrication process
set POLLUT ; # Types of pollutants
set DISTILLATION within {D_MODE, CRUD, DIST} ; # Pairs of the Distillation process
set REFORMING within {R_MODE, DIST, REF} ; # Pairs of the Reforming process
set DIST_R := setof{(m,d,r) in REFORMING}(d) ; # List of included components
set CRACKING within {CR_MODE, DIST, CRACK} ; # Pairs of the Cracking process
set DIST_CR := setof{(m,d,cr) in CRACKING}(d) ; # List of included components
set LUBRICATING within {L_MODE, DIST, LUBR} ; # Pairs of the Lubricating process
set DIST_L := setof{(m,d,l) in LUBRICATING}(d) ; # List of included components
set BLENDING within # Pairs of Intermediate and final products involved in blending
{DIST union REF union CRACK union LUBR, PROD} ;
set INTERMED:= setof{(i,j) in BLENDING}i ; # Set of Intermediate products before blending
### PARAMETERS
param nPeriod >= 0 ; # Number of weeks in the planning period
param nPeriodByYear >= 0 ; # Number of nPeriods in the Year
## Crude oil
param crude_Min{CRUD} = 0 ; # Minimum supply limits for each crude oil type
param crude_Max_capacity{c in CRUD} >= crude_Min[c] ; # Maximum supply limits for each crude oil type
param crude_Cost{CRUD, 1..nPeriod} >= 0 ; # Cost of crude oil per week
## Distillation
param distill_Yield{DISTILLATION} >= 0 ; # Yield of products
param distill_Pollute{D_MODE, CRUD, POLLUT} ; # Pollutant emissions
param distill_Cost{D_MODE, CRUD} >= 0 ; # Cost of process
param distill_Waste_Cost{D_MODE, CRUD} >= 0 ; # Residue disposal cost
param distill_Equipment_Setup_Period{D_MODE} >= 0 ; # Equipment setup period
param distill_Equipment_Setup_Cost{D_MODE} >= 0 ; # Equipment setup cost
param distill_Max_capacity{D_MODE} >= 0 ; # Maximum capacity
## Reforming
param reform_Yield{REFORMING} >= 0 ; # Yield of products
param reform_Pollute{R_MODE, DIST_R, POLLUT} ; # Pollutant emissions
param reform_Cost{R_MODE, DIST_R} >= 0 ; # Cost of process
param reform_Waste_Cost{R_MODE, DIST_R} >= 0 ; # Residue disposal cost
param reform_Max_capacity{R_MODE} >= 0 ; # Maximum capacity
param reform_Equipment_Setup_Period{R_MODE} >= 0 ; # Equipment setup period
param reform_Equipment_Setup_Cost{R_MODE} >= 0 ;# Equipment setup cost
## Cracking
param crack_Yield{CRACKING} >= 0 ; # Yield of products
param crack_Pollute{CR_MODE, DIST_CR, POLLUT} ; # Pollutant emissions
param crack_Cost{CR_MODE, DIST_CR} >= 0 ; # Cost of process
param crack_Waste_Cost{CR_MODE, DIST_CR} >= 0 ; # Residue disposal cost
param crack_Max_capacity{CR_MODE} >= 0 ; # Maximum capacity
param crack_Equipment_Setup_Period{CR_MODE} >= 0 ; # Equipment setup period
param crack_Equipment_Setup_Cost{CR_MODE} >=0 ; # Equipment setup cost
## Lubrication
param lube_Yield{LUBRICATING} >= 0 ; # Yield of products
param lube_Pollute{L_MODE, DIST_L, POLLUT} ; # Pollutant emissions
param lube_Waste_Cost{L_MODE, DIST_L} >= 0 ; # Residue disposal cost
param lube_Cost{L_MODE, DIST_L} >= 0 ; # Cost of process
param lube_Max_capacity{L_MODE} >= 0 ; # Maximum production of lube oil
param lube_Equipment_Setup_Period{L_MODE} >= 0 ;# Equipment setup period
param lube_Equipment_Setup_Cost{L_MODE} >= 0 ; # Equipment setup cost
param lube_limit_Min = 0 ; # Minimum production of lube oil
param lube_limit_Max >= lube_limit_Min ; # Maximum production of lube oil
## Intermediate components
param Intermed_Octane{INTERMED} >= 0 ; # Octane number
param Intermed_VaporPressure{INTERMED} >= 0 ; # Vapor pressure
## Blending
param blending_Cost{PROD} >= 0 ; # Cost of blending
## Products
param prod_Octane_Min{PROD} >= 0 ; # Minimum octane number for final products
param prod_VaporPressure_Max{PROD} >= 0 ; # Maximum vapor pressure for final products
param prod_Premium_Regular_Gas_Min >= 0 ; # Minimum production of premium gas
param prod_FuelOil_Ratio{INTERMED} >= 0 ; # Ratios for fuel oil production components
## Storage
param storage_Capacity{PROD} >=0 ; # Storage capacity for each product
param storage_Cost{PROD} >= 0 ; # Storage cost per product
param storage_Waste{PROD} >= 0 ; # Waste during storage
## Product delivery
param delivery_Cost{PROD, STAT} >= 0 ; # Delivery cost per product to each station
## Plant
param plant_Shutdown_Period >= 0 ; # Equipment setup period
param plant_Shutdown_Cost >= 0 ; # Equipment setup cost
param plant_Const_Cost >= 0 ; # Plant fixed costs
## Market
param seasonal_Base_Demand{PROD, 1..nPeriod} >= 0 ; # Base demand for products per week.
param seasonal_Base_Price {PROD, 1..nPeriod} >= 0 ; # Base price for products per week.
# Price elasticity
param nStep integer > 0 ; # Number of steps for price elasticity
param price_nStep_Value{1..nStep+1} ; # Step values for price elasticity
param demand_nStep_Value{1..nStep+1} ; # Step values for price elasticity
## Finance
param discount_Rate >= 0 ; # Discount rate for future cash flows
param initial_Cash >= 0 ; # Initial cash available
## Loans
set LOANS; # Set of loan periods
set LOAN_param; # Parameters of loans (term, interest, Max_Money)
param loan{LOANS, LOAN_param} >= 0 ; # Conditions for obtaining credit
### VARIABLES
## Plant working
var Plant_Working{t in 1..nPeriod} binary; # 1 if the plant is running. 0 if the plant is shutdown
## Distillation
var Crude_Supply{D_MODE, CRUD, 1..nPeriod} >= 0 ; # Amount of crude supplied
var Distill_X{D_MODE, 1..nPeriod} binary ; # Additional binary variable for selecting the operating mode of the equipment
## Reforming
var Distill_to_Reforming{R_MODE, DIST_R, 1..nPeriod} >= 0 ; # Quantity of distillation products used for Reforming
var Reform_X{R_MODE, 1..nPeriod} binary ; # Additional binary variable for selecting the operating mode of the equipment
## Cracking
var Distill_to_Cracking{CR_MODE, DIST_CR, 1..nPeriod} >= 0 ;# Quantity of distillation products used for Cracking
var Cracking_X{CR_MODE, 1..nPeriod} binary ; # Additional binary variable for selecting the operating mode of the equipment
## Lubricating
var Distill_to_Lubricating{L_MODE, DIST_L, 1..nPeriod} >= 0 ;# Quantity of distillation products used for Lubricating
var Lubricating_X{L_MODE, 1..nPeriod} binary ; # Additional binary variable for selecting the operating mode of the equipment
## Blending:
var Blending{BLENDING, 1..nPeriod} >= 0 ; # Amount of ingredients mixed to obtain final products
## Demand
var Demand{PROD, STAT, 1..nPeriod, 1..nStep} >= 0 ; # Demand for each pr oduct at each station over time
var X{PROD, STAT, 1..nPeriod, 1..nStep} binary ; # Additional binary variable for demand steps (1 if for product p in period t the price is selected at step nStep, or 0 otherwise)
## Storage
var Storage_Fraction{p in PROD, t in 1..nPeriod} = # Amount of each product in Storage each period
sum{tt in 1..t} (sum{(i,p) in BLENDING} Blending[i,p,tt]
- sum{s in STAT, n in 1..nStep} Demand[p,s,tt,n]) * (1-storage_Waste[p]/100) ;
## Loan
# Amount of loan taken every period
var Loan_In{l in LOANS, 1..nPeriod-1} >= 0 , <= loan[l,'Max_Money'] ;
# Amount of loan taken every period
var Loan_Out{l in LOANS, t in 2..nPeriod} = Loan_In[l,t-1] * (1+(loan[l, 'interest']/nPeriodByYear)/100);
## Pollutant emissions
var Waste_Pollutant{p in POLLUT, t in 1..nPeriod} =
# Pollution from waste disposal from the Distillation process
sum{m in D_MODE, c in CRUD} Crude_Supply[m,c,t] * (1 - sum{d in DIST}distill_Yield[m,c,d]) * distill_Pollute[m,c,p]
# Pollution from waste disposal from the Reforming process
+ sum{m in R_MODE, c in DIST_R} Distill_to_Reforming[m,c,t] * (1 - sum{d in REF} reform_Yield[m,c,d]) * reform_Pollute[m,c,p]
# Pollution from waste disposal from the Cracking process
+ sum{m in CR_MODE, c in DIST_CR} Distill_to_Cracking[m,c,t] * (1 - sum{d in CRACK} crack_Yield[m,c,d]) * crack_Pollute[m,c,p]
# Pollution from waste disposal from the Lubricating process
+ sum{m in L_MODE, c in DIST_L} Distill_to_Lubricating[m,c,t] * (1 - sum{d in LUBR} lube_Yield[m,c,d]) * lube_Pollute[m,c,p];
## Cash flow with incomes and costs
var CashFlow{t in 1..nPeriod} =
# sales income
sum{p in PROD, s in STAT, n in 1..nStep} Demand[p,s,t,n] * (seasonal_Base_Price[p,t] * (1 + price_nStep_Value[n]/100) - delivery_Cost[p,s])
# minus the cost of purchasing crude oil + the costs of the Distillation process + costs for disposal of waste from the Distillation process
- sum{m in D_MODE, c in CRUD} Crude_Supply[m,c,t] * (crude_Cost[c,t] + distill_Cost[m,c] + (1 - sum{d in DIST}distill_Yield[m,c,d]) * distill_Waste_Cost[m,c])
# minus the costs of the Reforming process + costs for disposal of waste from the Reforming process
- sum{m in R_MODE, c in DIST_R} Distill_to_Reforming[m,c,t] * (reform_Cost[m,c] + (1 - sum{d in REF} reform_Yield[m,c,d]) * reform_Waste_Cost[m,c])
# minus the costs of the Cracking process + costs for disposal of waste from the Cracking process
- sum{m in CR_MODE, c in DIST_CR} Distill_to_Cracking[m,c,t] * (crack_Cost[m,c] + (1 - sum{d in CRACK} crack_Yield[m,c,d]) * crack_Waste_Cost[m,c])
# minus the costs of the Lubricating process + costs for disposal of waste from the Lubricating process
- sum{m in L_MODE, c in DIST_L} Distill_to_Lubricating[m,c,t] * (lube_Cost[m,c] + (1 - sum{d in LUBR} lube_Yield[m,c,d]) * lube_Waste_Cost[m,c])
# minus the costs of reconfiguring equipment (if available)
- (if t > 1 then /*Nonliner piece*/
# Distillation equipment
sum{m in D_MODE} (if Distill_X[m,t] - Distill_X[m,t-1] > 0 then distill_Equipment_Setup_Cost[m] else 0)
# Reforming equipment
+ sum{m in R_MODE} (if Reform_X[m,t] - Reform_X[m,t-1] > 0 then reform_Equipment_Setup_Cost[m] else 0)
# Cracking equipment
+ sum{m in CR_MODE} (if Cracking_X[m,t] - Cracking_X[m,t-1] > 0 then crack_Equipment_Setup_Cost[m] else 0)
# Lubricating equipment
+ sum{m in L_MODE}(if Lubricating_X[m,t] - Lubricating_X[m,t-1] > 0 then lube_Equipment_Setup_Cost[m] else 0)
else 0)
# minus the cost of the Blending
- sum{(i,p) in BLENDING} Blending[i,p,t] * blending_Cost[p]
# minus cost of shutdown
- (1 - Plant_Working[t]) * plant_Shutdown_Cost
# minus the storage cost
- sum{p in PROD} Storage_Fraction[p,t] * storage_Cost[p]
# minus fixed plant costs
- plant_Const_Cost
# plus the amount of the loan received
+ (if t = nPeriod then 0 else sum{l in LOANS} Loan_In[l,t])
# minus the amount of repaid loans with accrued interest
- (if t = 1 then 0 else sum{l in LOANS} Loan_Out[l,t]);
### OBJECTIVE FUNCTION
# Maximize the total profit considering all incomes and costs, discounted by the discount rate
maximize Total_Profit:
sum{t in 1..nPeriod} CashFlow[t] / (1 + (discount_Rate/nPeriodByYear)/100)^t ;
### CONSTRAINTS
subject to
## Distillation
# Ensure that total supply of crude oil does not exceed the maximum capacity.
Crude_Supply_Min_Max{c in CRUD, t in 1..nPeriod}:crude_Min[c] <= sum{m in D_MODE} Crude_Supply[m,c,t] <= crude_Max_capacity[c];
# Ensure distillation capacity does not exceed the maximum. Сapacity is reduced during downtime caused by equipment reconfiguring.
DistillCapacity_Max {m in D_MODE, t in 1..nPeriod}: sum{c in CRUD} Crude_Supply[m,c,t] <= distill_Max_capacity [m]
/* Nonliner piece*/ * (if t > 1 then (if Distill_X[m,t] > Distill_X[m,t-1] then 1 - distill_Equipment_Setup_Period[m] else 1) else 1) ;
# Ensure only one mode per period
ForEachPeriodOnlyOne_Distill_X { t in 1..nPeriod}: sum{m in D_MODE} Distill_X[m,t] <= 1 ;
# Ensure that Crude_Supply > 0 only when Distill_X > 0
Distill_{m in D_MODE, t in 1..nPeriod}: sum{c in CRUD} Crude_Supply[m,c,t] <= Distill_X[m,t] * 10e5;
## Reforming
# Ensure reforming capacity does not exceed the maximum. Сapacity is reduced during downtime caused by equipment reconfiguring.
Reforming_Capacity_Max {m in R_MODE, t in 1..nPeriod}: sum{c in DIST_R} Distill_to_Reforming[m,c,t] <= reform_Max_capacity[m]
/* Nonliner piece*/ * (if t > 1 then (if Reform_X[m,t] > Reform_X[m,t-1] then 1 - reform_Equipment_Setup_Period[m] else 1) else 1);
# Ensure only one mode per period
ForEachPeriodOnlyOne_Reform_X { t in 1..nPeriod}: sum{m in R_MODE} Reform_X[m,t] <= 1 ;
# Ensure that Distill_to_Reforming > 0 only when Reform_X > 0
Reform_{m in R_MODE, t in 1..nPeriod}:sum{c in DIST_R}Distill_to_Reforming[m,c,t] <= Reform_X[m,t] * 10e5;
## Cracking
# Ensure cracking capacity does not exceed the maximum. Сapacity is reduced during downtime caused by equipment reconfiguring.
CrackingCapacity_Max {m in CR_MODE, t in 1..nPeriod}: sum{c in DIST_CR} Distill_to_Cracking[m,c,t] <= crack_Max_capacity[m]
/* Nonliner piece*/ * (if t > 1 then (if Cracking_X[m,t] > Cracking_X[m,t-1] then 1 - crack_Equipment_Setup_Period[m] else 1) else 1);
# Ensure only one mode per period
ForEachPeriodOnlyOne_Cracking_X { t in 1..nPeriod}: sum{m in CR_MODE} Cracking_X[m,t] <= 1 ;
# Ensure that Distill_to_Cracking > 0 only when Cracking_X > 0
Cracking_{m in CR_MODE, t in 1..nPeriod}: sum{c in DIST_CR} Distill_to_Cracking[m,c,t] <= Cracking_X[m,t] * 10e5;
## Lubricating
# Ensure cracking does not exceed the minimum & maximum volume
Lube_Oil_Min_Max {t in 1..nPeriod}:
lube_limit_Min <= sum{(m,d,l)in LUBRICATING} Distill_to_Lubricating[m,d,t] * lube_Yield[m,d,l] <= lube_limit_Max ;
# Сapacity is reduced during downtime caused by equipment reconfiguring.
Lube_Oil_Capacity_Max {m in L_MODE, t in 1..nPeriod}: sum{c in DIST_L} Distill_to_Lubricating[m,c,t] <= lube_Max_capacity[m]
/* Nonliner piece*/ * (if t > 1 then (if Lubricating_X[m,t] > Lubricating_X[m,t-1] then 1 - lube_Equipment_Setup_Period[m] else 1) else 1); # Nonliner piece
# Ensure only one mode per period
ForEachPeriodOnlyOne_Lubricating_X { t in 1..nPeriod}: sum{m in L_MODE} Lubricating_X[m,t] <= 1 ;
# Ensure that Distill_to_Lubricating> 0 only when Lubricating_X > 0
Lubricating_{m in L_MODE, t in 1..nPeriod}: sum{c in DIST_L}Distill_to_Lubricating[m,c,t] <= Lubricating_X[m,t] * 10e5;
## Blending
PremiumRegularGasRatio {t in 1..nPeriod}: # Premium gasoline production: at least 40% of regular gasoline production
sum{(i,p) in BLENDING: p='Premium Gasoline'} Blending[i,p,t] >=
sum{(i,p) in BLENDING: p='Regular Gasoline'} Blending[i,p,t] * prod_Premium_Regular_Gas_Min/100 ;
OctaneNumberMin {p in PROD, t in 1..nPeriod: p = 'Premium Gasoline'}:# Ensure octane number requirements for final products
sum{(i,p) in BLENDING} Blending[i,p,t] * Intermed_Octane[i] >=
sum{(ii,p) in BLENDING} Blending[ii,p,t] * prod_Octane_Min[p] ;
OctaneNumberMin_2 {p in PROD, t in 1..nPeriod: p = 'Regular Gasoline'}:# Ensure octane number requirements for final products
sum{(i,p) in BLENDING} Blending[i,p,t] * Intermed_Octane[i] >=
sum{(ii,p) in BLENDING} Blending[ii,p,t] * prod_Octane_Min[p] ;
VaporPressure_Max {p in PROD, t in 1..nPeriod: p='Jet Fuel'}:# Ensure vapor pressure limits for products
sum{(i,p) in BLENDING} Blending[i,p,t] * Intermed_VaporPressure[i] <=
sum{(i,p) in BLENDING} Blending[i,p,t] * prod_VaporPressure_Max[p] ;
FuelOilRatio {(i,p) in BLENDING, t in 1..nPeriod: p = 'Fuel Oil'}: # Maintain the correct ratio for fuel oil production
Blending['Residuum',p, t] = Blending[i,p,t] / prod_FuelOil_Ratio[i] ;
## Storage
# Ensure storage fractions are non-negative and within capacity
Storage_non_negative {p in PROD, t in 1..nPeriod}:
0 <= Storage_Fraction[p,t] <= storage_Capacity[p];
## Financial calculations
CashFlow_Balance{t in 1..nPeriod}: # Cash flow balance
initial_Cash
+ sum{tt in 1..t}CashFlow[tt] >= 0;
## Ensure sufficient distillation output
Distillation_Out {d in DIST, t in 1..nPeriod}:
sum{m in D_MODE, c in CRUD} Crude_Supply[m,c,t] * distill_Yield[m,c,d]
>=
sum{m in R_MODE, dd in DIST_R: dd=d} Distill_to_Reforming[m,dd,t]
+ sum{m in CR_MODE, dd in DIST_CR: dd=d} Distill_to_Cracking[m,dd,t]
+ sum{m in L_MODE, dd in DIST_L: dd=d} Distill_to_Lubricating[m,dd,t] ;
## Balance INTERMED products before blending
INTERMED_Balance{i in INTERMED, t in 1..nPeriod}:
sum{(i,p) in BLENDING} Blending[i,p,t] <=
sum{(m,c,d) in DISTILLATION:d=i} Crude_Supply[m,c,t] * distill_Yield[m,c,d]
- sum{m in R_MODE, d in DIST_R: d=i} Distill_to_Reforming[m,d,t]
- sum{m in CR_MODE, d in DIST_CR: d=i} Distill_to_Cracking[m,d,t]
- sum{m in L_MODE, d in DIST_L: d=i} Distill_to_Lubricating[m,d,t]
+ sum{(m,d,r) in REFORMING: r=i} Distill_to_Reforming[m,d,t] * reform_Yield[m,d,r]
+ sum{(m,d,cr) in CRACKING: cr=i} Distill_to_Cracking[m,d,t] * crack_Yield[m,d,cr]
+ sum{(m,d,l) in LUBRICATING: l=i} Distill_to_Lubricating[m,d,t] * lube_Yield[m,d,l] ;
## Prices elastisity
ForEachPeriodOnlyOne_X {p in PROD, s in STAT, t in 1..nPeriod}:
sum{i in 1..nStep} X [p,s,t,i] = 1 ; # Ensure only one price per product per period
# Double restriction. Ensure demand is within the range dictated by price steps.
# The constraint of type min must be set after solving a model without this constraint. #Use Min constraint after ensuring that it does not conflict with other model constraints.
Demand_Min {p in PROD, s in STAT, t in 1..nPeriod, n in 1..nStep: p!='Lube Oil'}:
Demand[p,s,t,n] >= X[p,s,t,n] * seasonal_Base_Demand[p,t] * (1+demand_nStep_Value[n]/100) ;
Demand_Max {p in PROD, s in STAT, t in 1..nPeriod, n in 1..nStep}:
Demand[p,s,t,n] <= X[p,s,t,n] * seasonal_Base_Demand[p,t] * (1+demand_nStep_Value[n+1]/100) ;
## Shutdown contstraints
# The number of working periods is equal to the total number of periods under consideration minus the duration of the planned suspension
Plant_Working_nPeriods: sum{t in 1..nPeriod - plant_Shutdown_Period + 1} Plant_Working[t] = nPeriod - plant_Shutdown_Period;
# Additionally, there is a restriction in case of a longer (more than 1 period) plant shutdown.
Shutdown_Distill{t in 1..nPeriod - plant_Shutdown_Period + 1}:
sum{m in D_MODE, c in CRUD, tt in 0..plant_Shutdown_Period-1} Crude_Supply[m,c,t+tt] <= Plant_Working[t] * 10e5;
5. Data change#
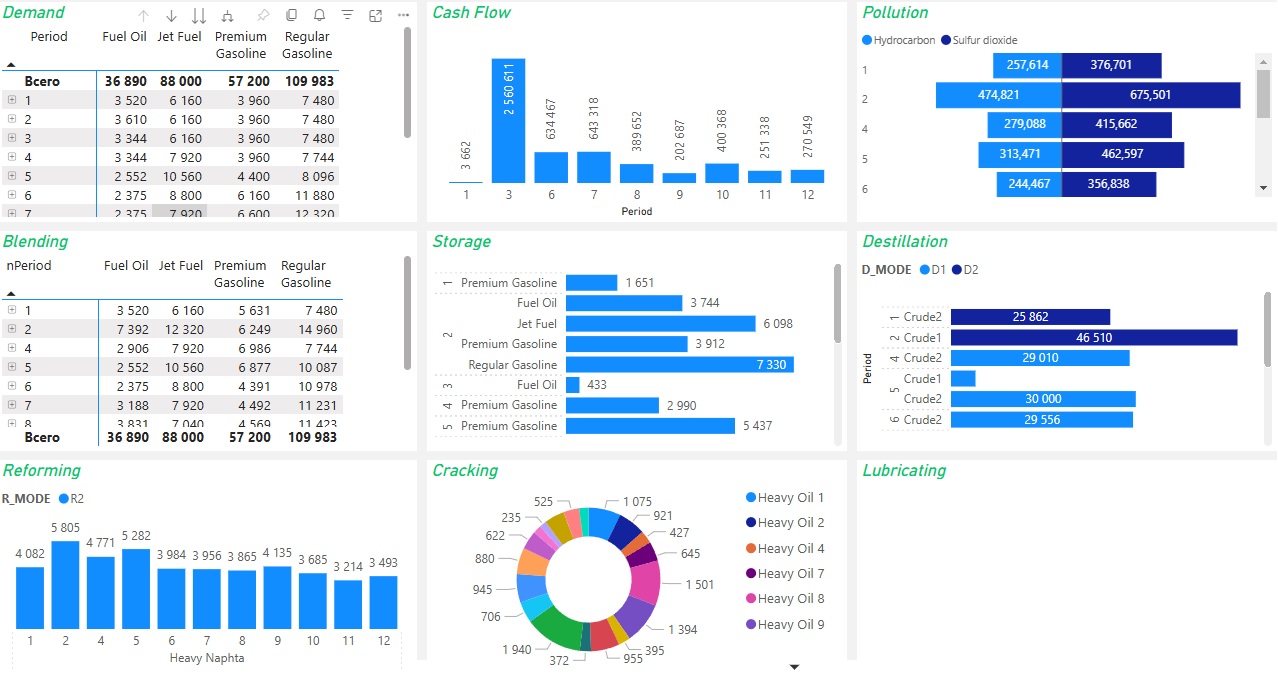
You can change model parameters directly in a Power BI report.

5. Download Data from Power BI Report#
Retrieve the required data for analysis.
pages = (
report.get_pages()
) # Retrieve the list of pages from the report object, storing them in the 'pages' variable.
# The following lines are commented out but would iterate through the list of pages if uncommented.
# for page in range(len(pages)): # Loop over each page index from 0 to the total number of pages.
# print("displayName:", pages[page]['displayName']," name:", pages[page]['name']) # For each page, print its 'displayName' (the human-readable name) and 'name' (the internal identifier).
range_of_visual = { # List visuals for import data to AMPL parameters
"a6ee369779ca1dbbe625": ["CRUD", "crude_Max_capacity", "crude_Cost"],
"ReportSectione9e707e99075fef5f637": [
"DIST",
"POLLUT",
"D_MODE",
"distill_Waste_Cost",
"distill_Max_capacity",
"distill_Equipment_Setup_Period",
"distill_Pollute",
"distill_Cost",
"distill_Yield",
"distill_Equipment_Setup_Cost",
],
"1f30731c20476b22e3b8": [
"REF",
"R_MODE",
"reform_Max_capacity",
"reform_Equipment_Setup_Period",
"reform_Equipment_Setup_Cost",
"reform_Yield",
"reform_Cost",
"reform_Pollute",
"reform_Waste_Cost",
],
"baaf6d948d8009021852": [
"CRACK",
"CR_MODE",
"crack_Yield",
"crack_Pollute",
"crack_Cost",
"crack_Waste_Cost",
"crack_Max_capacity",
"crack_Equipment_Setup_Period",
"crack_Equipment_Setup_Cost",
],
"df4105df5589821b0042": [
"LUBR",
"L_MODE",
"lube_Max_capacity",
"lube_Equipment_Setup_Period",
"lube_Equipment_Setup_Cost",
"lube_limit_Max",
"lube_Yield",
"lube_Pollute",
"lube_Cost",
"lube_Waste_Cost",
],
"5f6474c4e0a5741fa523": [
"PROD",
"prod_FuelOil_Ratio",
"prod_VaporPressure_Max",
"prod_Premium_Regular_Gas_Min",
"blending_recipe",
"prod_Octane_Min",
"Intermed_VaporPressure",
"Intermed_Octane",
"blending_Cost",
],
"824aaabf4036f0ccfbb2": [
"STAT",
"storage_Capacity",
"storage_Cost",
"storage_Waste",
"delivery_Cost",
],
"a0c8f0fc396f1f12c937": [
"plant_Const_Cost",
"plant_Shutdown_Period",
"plant_Shutdown_Cost",
"initial_Cash",
"discount_Rate",
],
"015cea0c3cc0be908cc3": ["LOAN_param", "LOANS", "loan"],
"eac0f7120065aad83ca0": [
"demand_nStep_Value",
"seasonal_Base_Price",
"seasonal_Base_Demand",
"price_nStep_Value",
],
}
ampl_ = (
dict()
) # Initialize an empty dictionary to store data for each visual param element
for key_s in range_of_visual: # Loop through each page in the list of Power BI pages
report.set_active_page(
key_s
) # Set the current page as active in the Power BI report
visuals = report.visuals_on_page(
key_s
) # Get the list of visual elements on the active page
for i in range(
len(range_of_visual[key_s])
): # Loop through each visual element on the active page
# print(range_of_visual[key_s][i]) # Debugging statement to print the current visual element name
visual = next(
filter(lambda visual: visual["title"] == range_of_visual[key_s][i], visuals)
) # Find the visual element from the active page's visuals list that matches the name in range_of_visual_param
summarized_exported_data = report.export_visual_data(
key_s,
visual["name"],
rows=1000,
export_data_type=models.ExportDataType.SUMMARIZED.value,
) # Export summarized data from the visual element
data = StringIO(
summarized_exported_data
) # Convert the exported data to a string format for processing
ampl_[range_of_visual[key_s][i]] = pd.read_csv(
data
) # Read the data as a CSV and store it in the dictionary
# After looping through all pages and visuals, reset to the main page
report.set_active_page(pages[0]["name"]) # Re-activate the main page
6. Load Data into AMPL#
Seamlessly import your data into the AMPL system.
### SETS
ampl.set["DISTILLATION"] = ampl_["distill_Yield"].apply(
lambda row: (row["D_MODE"], row["CRUD"], row["DIST"]), axis=1
)
ampl.set["REFORMING"] = ampl_["reform_Yield"].apply(
lambda row: (row["R_MODE"], row["DIST_R"], row["REF"]), axis=1
)
ampl.set["CRACKING"] = ampl_["crack_Yield"].apply(
lambda row: (row["CR_MODE"], row["DIST_CR"], row["CRACK"]), axis=1
)
ampl.set["LUBRICATING"] = ampl_["lube_Yield"].apply(
lambda row: (row["L_MODE"], row["DIST_L"], row["LUBR"]), axis=1
)
ampl.set["BLENDING"] = ampl_["blending_recipe"].apply(
lambda row: (row["INTERMED"], row["PROD"]), axis=1
)
### PARAMETERS
ampl.param["nPeriod"] = len(set(ampl_["crude_Cost"]["nPeriod"]))
ampl.param["nStep"] = len(set(ampl_["demand_nStep_Value"]["nStep"])) - 1
ampl.param["nPeriodByYear"] = 12
sets_ = [
"CRUD",
"DIST",
"POLLUT",
"D_MODE",
"REF",
"R_MODE",
"CRACK",
"CR_MODE",
"LUBR",
"L_MODE",
"PROD",
"LOAN_param",
"LOANS",
"STAT",
]
for key_dict in ampl_.keys(): # Loop through all keys in the 'ampl_' dictionary
if key_dict in sets_: # Check if the current key is one of the predefined sets
if len(ampl_[key_dict]) > 1: # If the DataFrame with more than one row
ampl.set[key_dict] = set(
ampl_[key_dict].squeeze()
) # Set the parameter in 'ampl'
else: # If only one row, directly extract the value and create a set
ampl.set[key_dict] = set(ampl_[key_dict][key_dict])
else:
df = ampl_[
key_dict
] # Get the dataframe corresponding to the current key from the 'ampl_param' dictionary
set_of_columns = df.loc[
:, df.columns != key_dict
].columns.tolist() # Get a list of indexing columns (excluding column 'key_var')
if set_of_columns: # If there are any remaining columns in 'r_df'
if key_dict not in {
"blending_recipe"
}: # Check if the current key is not 'blending_recipe'. we use 'blending_recipe' only for set
ampl.param[key_dict] = df.set_index(set_of_columns)[
key_dict
] # Set the parameter in 'ampl' with 'key_var' as the index based on the remaining columns
else:
ampl.param[key_dict] = ampl_[
key_dict
].squeeze() # Assign the squeezed version (i.e., reduced to lowest dimension) of 'ampl_param[key_var]' to 'ampl.param'
7. Solve the Problem#
Run the optimization model to get your solution
%%ampl_eval
option solver cbc; # Choosing a solver
# Defining Output Settings
option show_stats 1; # (1) Show statistical information about the size of the problem. Default 0 (statistics are not displayed)
option display_1col 0; # Data Display Settings
option omit_zero_rows 1; # Hide rows with 0 values. Default (0)
solve; # Solve the model
Presolve eliminates 14 constraints.
Substitution eliminates 107 variables.
Adjusted problem:
1259 variables:
372 binary variables
96 nonlinear variables
791 linear variables
1343 constraints; 13845 nonzeros
99 nonlinear constraints
1244 linear constraints
97 equality constraints
1190 inequality constraints
56 range constraints
1 nonlinear objective; 899 nonzeros.
cbc 2.10.10:cbc 2.10.10: optimal solution; objective 2783808.156
2900 simplex iterations
2900 barrier iterations
20 branching nodes
------------ WARNINGS ------------
WARNING: "Tolerance violations"
Type MaxAbs [Name] MaxRel [Name]
objective(s) 1E+05 4E-02
Documentation: mp.ampl.com/modeling-tools.html#automatic-solution-check.
assert ampl.solve_result == "solved", ampl.solve_result
6. Display the solution#
%%ampl_eval
# Display the values of the variables:
display Plant_Working, Crude_Supply, Distill_to_Reforming, Distill_to_Cracking, Distill_to_Lubricating, Blending, OctaneNumberMin, VaporPressure_Max, Storage_Fraction, Demand, Loan_In, Loan_Out, CashFlow, Waste_Pollutant;
# Calculate and print the octane number for each product over all periods.
printf {p in PROD, t in 1..nPeriod}: "Octane number for products: %u %s %6.2f\n", t, p, sum{(i,p) in BLENDING} Blending[i,p,t] * Intermed_Octane[i] / sum{(ii,p) in BLENDING}(if Blending[ii,p,t] = 0 then 1 else Blending[ii,p,t]);
# Calculate and print the vapor pressure limits for "Jet Fuel" over all periods.
printf {p in PROD, t in 1..nPeriod: p='Jet Fuel'}: "Vapor pressure limits of product Jet Fuel: %u %s %6.2f\n", t, p, sum{(i,p) in BLENDING} Blending[i,p,t] * Intermed_VaporPressure[i] / (if sum{(ii,p) in BLENDING} Blending[ii,p,t] = 0 then 1 else sum{(ii,p) in BLENDING}Blending[ii,p,t]) ;
# Calculate and print the percentage ratio of "Premium Gasoline" to "Regular Gasoline" over all periods.
printf {t in 1..nPeriod}: "Premium / Regular percentage: %u %6.2f\n", t,
sum{(i,p) in BLENDING: p ='Premium Gasoline'} Blending[i,p,t] / (if sum{(ii,pp) in BLENDING: pp ='Regular Gasoline'}Blending[ii,pp,t] = 0 then 1 else sum{(ii,pp) in BLENDING: pp ='Regular Gasoline'}Blending[ii,pp,t]) ;
# Calculate and print the production ratio for "Fuel Oil" for each blending component over all periods.
printf {(i,p) in BLENDING, t in 1..nPeriod: p='Fuel Oil'}: "Production Fuel Oil ratio: %u %s %6.2f\n", t, i,
Blending[i,p,t] / (if Blending['Residuum',p,t] = 0 then 1 else Blending['Residuum',p,t]);
Plant_Working [*] :=
1 1 2 1 4 1 5 1 6 1 7 1 8 1 9 1 10 1 11 1 12 1
;
# $2 = Distill_to_Reforming
: Crude_Supply $2 :=
D1 Crude1 5 4341.18 .
D1 Crude2 4 27235.2 .
D1 Crude2 5 30000 .
D1 Crude2 6 30000 .
D1 Crude2 7 30000 .
D1 Crude2 8 30000 .
D1 Crude2 9 30000 .
D1 Crude2 10 25667.5 .
D1 Crude2 11 22825.2 .
D1 Crude2 12 25149.7 .
D2 Crude1 1 25116.9 .
D2 Crude1 2 40000 .
D2 Crude1 7 4.01943e-26 .
D2 Crude1 8 6.04316e-12 .
D2 Crude2 2 9176.88 .
R2 'Heavy Naphta' 1 . 3289.03
R2 'Heavy Naphta' 2 . 6584.9
R2 'Heavy Naphta' 4 . 4360.94
R2 'Heavy Naphta' 5 . 5536.63
R2 'Heavy Naphta' 6 . 4019.59
R2 'Heavy Naphta' 7 . 3760.46
R2 'Heavy Naphta' 8 . 3894.68
R2 'Heavy Naphta' 9 . 4147.09
R2 'Heavy Naphta' 10 . 3685.4
R2 'Heavy Naphta' 11 . 3214.41
R2 'Heavy Naphta' 12 . 3492.84
;
# $1 = Distill_to_Cracking
# $2 = Distill_to_Lubricating
: $1 $2 Blending :=
CR2 'Heavy Oil' 1 905.436 . .
CR2 'Heavy Oil' 2 1555.14 . .
CR2 'Heavy Oil' 7 1418 . .
CR2 'Heavy Oil' 8 1394.04 . .
CR2 'Heavy Oil' 9 1394.04 . .
CR2 'Heavy Oil' 11 395.345 . .
CR2 'Heavy Oil' 12 954.904 . .
CR2 'Light Oil' 1 835.253 . .
CR2 'Light Oil' 2 1601.69 . .
CR2 'Light Oil' 4 871.527 . .
CR2 'Light Oil' 5 997.913 . .
CR2 'Light Oil' 6 1014.29 . .
CR2 'Light Oil' 7 871.887 . .
CR2 'Light Oil' 8 235.099 . .
CR2 'Light Oil' 9 235.099 . .
CR2 'Light Oil' 10 674.298 . .
CR2 'Light Oil' 11 524.828 . .
CR2 'Light Oil' 12 308.239 . .
'Cracked Oil' 'Fuel Oil' 1 . . 971.979
'Cracked Oil' 'Fuel Oil' 2 . . 1769.69
'Cracked Oil' 'Fuel Oil' 4 . . 522.916
'Cracked Oil' 'Fuel Oil' 5 . . 598.748
'Cracked Oil' 'Fuel Oil' 6 . . 554.286
'Cracked Oil' 'Fuel Oil' 7 . . 611.245
'Cracked Oil' 'Fuel Oil' 8 . . 865.96
'Cracked Oil' 'Fuel Oil' 9 . . 865.96
'Cracked Oil' 'Fuel Oil' 10 . . 404.579
'Cracked Oil' 'Fuel Oil' 11 . . 520.476
'Cracked Oil' 'Fuel Oil' 12 . . 681.494
'Cracked Oil' 'Jet Fuel' 6 . . 54.2857
'Cracked Oil' 'Jet Fuel' 7 . . 649.249
'Cracked gasoline' 'Premium Gasoline' 1 . . 591.834
'Cracked gasoline' 'Premium Gasoline' 4 . . 296.319
'Cracked gasoline' 'Premium Gasoline' 7 . . 778.563
'Cracked gasoline' 'Premium Gasoline' 8 . . 553.907
'Cracked gasoline' 'Premium Gasoline' 10 . . 229.261
'Cracked gasoline' 'Premium Gasoline' 12 . . 429.469
'Cracked gasoline' 'Regular Gasoline' 2 . . 1073.32
'Cracked gasoline' 'Regular Gasoline' 5 . . 339.291
'Cracked gasoline' 'Regular Gasoline' 6 . . 344.857
'Cracked gasoline' 'Regular Gasoline' 9 . . 553.907
'Cracked gasoline' 'Regular Gasoline' 11 . . 312.859
'Heavy Naphta' 'Premium Gasoline' 2 . . 315.576
'Heavy Naphta' 'Premium Gasoline' 5 . . 731.602
'Heavy Naphta' 'Regular Gasoline' 1 . . 1483.19
'Heavy Naphta' 'Regular Gasoline' 2 . . 2443.13
'Heavy Naphta' 'Regular Gasoline' 4 . . 541.394
'Heavy Naphta' 'Regular Gasoline' 6 . . 1380.41
'Heavy Naphta' 'Regular Gasoline' 7 . . 1639.54
'Heavy Naphta' 'Regular Gasoline' 8 . . 1505.32
'Heavy Naphta' 'Regular Gasoline' 9 . . 1252.91
'Heavy Naphta' 'Regular Gasoline' 10 . . 934.749
'Heavy Naphta' 'Regular Gasoline' 11 . . 894.134
'Heavy Naphta' 'Regular Gasoline' 12 . . 1034.1
'Heavy Oil' 'Fuel Oil' 1 . . 728.984
'Heavy Oil' 'Fuel Oil' 2 . . 1327.27
'Heavy Oil' 'Fuel Oil' 4 . . 392.187
'Heavy Oil' 'Fuel Oil' 5 . . 449.061
'Heavy Oil' 'Fuel Oil' 6 . . 415.714
'Heavy Oil' 'Fuel Oil' 7 . . 458.434
'Heavy Oil' 'Fuel Oil' 8 . . 649.47
'Heavy Oil' 'Fuel Oil' 9 . . 649.47
'Heavy Oil' 'Fuel Oil' 10 . . 303.434
'Heavy Oil' 'Fuel Oil' 11 . . 390.357
'Heavy Oil' 'Fuel Oil' 12 . . 511.12
'Heavy Oil' 'Jet Fuel' 1 . . 3137.79
'Heavy Oil' 'Jet Fuel' 2 . . 6369.43
'Heavy Oil' 'Jet Fuel' 4 . . 4782.5
'Heavy Oil' 'Jet Fuel' 5 . . 6119.18
'Heavy Oil' 'Jet Fuel' 6 . . 5284.29
'Heavy Oil' 'Jet Fuel' 7 . . 3823.56
'Heavy Oil' 'Jet Fuel' 8 . . 3656.49
'Heavy Oil' 'Jet Fuel' 9 . . 3656.49
'Heavy Oil' 'Jet Fuel' 10 . . 4573.39
'Heavy Oil' 'Jet Fuel' 11 . . 3551.09
'Heavy Oil' 'Jet Fuel' 12 . . 3312.41
'Light Naphta' 'Premium Gasoline' 2 . . 6084.76
'Light Naphta' 'Premium Gasoline' 4 . . 4085.28
'Light Naphta' 'Premium Gasoline' 5 . . 4934.12
'Light Naphta' 'Premium Gasoline' 7 . . 3582.13
'Light Naphta' 'Premium Gasoline' 8 . . 3601.32
'Light Naphta' 'Premium Gasoline' 9 . . 4435.2
'Light Naphta' 'Premium Gasoline' 10 . . 3604.3
'Light Naphta' 'Premium Gasoline' 11 . . 3326.4
'Light Naphta' 'Premium Gasoline' 12 . . 3524.21
'Light Naphta' 'Regular Gasoline' 1 . . 3014.03
'Light Naphta' 'Regular Gasoline' 6 . . 4500
'Light Naphta' 'Regular Gasoline' 7 . . 917.875
'Light Naphta' 'Regular Gasoline' 8 . . 898.682
'Light Naphta' 'Regular Gasoline' 9 . . 64.8
'Light Naphta' 'Regular Gasoline' 10 . . 245.829
'Light Naphta' 'Regular Gasoline' 11 . . 97.3843
'Light Naphta' 'Regular Gasoline' 12 . . 248.238
'Light Oil' 'Fuel Oil' 1 . . 2429.95
'Light Oil' 'Fuel Oil' 2 . . 4424.23
'Light Oil' 'Fuel Oil' 4 . . 1307.29
'Light Oil' 'Fuel Oil' 5 . . 1496.87
'Light Oil' 'Fuel Oil' 6 . . 1385.71
'Light Oil' 'Fuel Oil' 7 . . 1528.11
'Light Oil' 'Fuel Oil' 8 . . 2164.9
'Light Oil' 'Fuel Oil' 9 . . 2164.9
'Light Oil' 'Fuel Oil' 10 . . 1011.45
'Light Oil' 'Fuel Oil' 11 . . 1301.19
'Light Oil' 'Fuel Oil' 12 . . 1703.73
'Light Oil' 'Jet Fuel' 5 . . 426.158
'Light Oil' 'Jet Fuel' 10 . . 367.655
'Medium Naphta' 'Premium Gasoline' 1 . . 2206.9
'Medium Naphta' 'Premium Gasoline' 4 . . 645.91
'Medium Naphta' 'Premium Gasoline' 5 . . 58.9735
'Medium Naphta' 'Premium Gasoline' 6 . . 2683.66
'Medium Naphta' 'Regular Gasoline' 1 . . 2565.31
'Medium Naphta' 'Regular Gasoline' 2 . . 9802.45
'Medium Naphta' 'Regular Gasoline' 4 . . 6162.89
'Medium Naphta' 'Regular Gasoline' 5 . . 8309.26
'Medium Naphta' 'Regular Gasoline' 6 . . 4816.34
'Medium Naphta' 'Regular Gasoline' 7 . . 7500
'Medium Naphta' 'Regular Gasoline' 8 . . 7500
'Medium Naphta' 'Regular Gasoline' 9 . . 7500
'Medium Naphta' 'Regular Gasoline' 10 . . 6416.87
'Medium Naphta' 'Regular Gasoline' 11 . . 5706.31
'Medium Naphta' 'Regular Gasoline' 12 . . 6287.42
'Reformed gasoline' 'Premium Gasoline' 1 . . 1161.26
'Reformed gasoline' 'Premium Gasoline' 2 . . 1519.66
'Reformed gasoline' 'Premium Gasoline' 4 . . 1053.54
'Reformed gasoline' 'Premium Gasoline' 5 . . 1815.26
'Reformed gasoline' 'Premium Gasoline' 6 . . 1789.11
'Reformed gasoline' 'Premium Gasoline' 7 . . 274.491
'Reformed gasoline' 'Premium Gasoline' 8 . . 395.824
'Reformed gasoline' 'Premium Gasoline' 9 . . 844.8
'Reformed gasoline' 'Premium Gasoline' 10 . . 566.443
'Reformed gasoline' 'Premium Gasoline' 11 . . 633.6
'Reformed gasoline' 'Premium Gasoline' 12 . . 446.319
'Reformed gasoline' 'Regular Gasoline' 1 . . 417.473
'Reformed gasoline' 'Regular Gasoline' 2 . . 1641.09
'Reformed gasoline' 'Regular Gasoline' 4 . . 1039.71
'Reformed gasoline' 'Regular Gasoline' 5 . . 842.321
'Reformed gasoline' 'Regular Gasoline' 6 . . 140.296
'Reformed gasoline' 'Regular Gasoline' 7 . . 1530.53
'Reformed gasoline' 'Regular Gasoline' 8 . . 1473.62
'Reformed gasoline' 'Regular Gasoline' 9 . . 1145.8
'Reformed gasoline' 'Regular Gasoline' 10 . . 1202.55
'Reformed gasoline' 'Regular Gasoline' 11 . . 909.315
'Reformed gasoline' 'Regular Gasoline' 12 . . 1230.25
Residuum 'Fuel Oil' 1 . . 242.995
Residuum 'Fuel Oil' 2 . . 442.423
Residuum 'Fuel Oil' 4 . . 130.729
Residuum 'Fuel Oil' 5 . . 149.687
Residuum 'Fuel Oil' 6 . . 138.571
Residuum 'Fuel Oil' 7 . . 152.811
Residuum 'Fuel Oil' 8 . . 216.49
Residuum 'Fuel Oil' 9 . . 216.49
Residuum 'Fuel Oil' 10 . . 101.145
Residuum 'Fuel Oil' 11 . . 130.119
Residuum 'Fuel Oil' 12 . . 170.373
Residuum 'Jet Fuel' 1 . . 3022.21
Residuum 'Jet Fuel' 2 . . 5950.57
Residuum 'Jet Fuel' 4 . . 3137.5
Residuum 'Jet Fuel' 5 . . 4014.67
Residuum 'Jet Fuel' 6 . . 3461.43
Residuum 'Jet Fuel' 7 . . 3447.19
Residuum 'Jet Fuel' 8 . . 3383.51
Residuum 'Jet Fuel' 9 . . 3383.51
Residuum 'Jet Fuel' 10 . . 2978.95
Residuum 'Jet Fuel' 11 . . 2608.91
Residuum 'Jet Fuel' 12 . . 2847.59
;
: OctaneNumberMin VaporPressure_Max Storage_Fraction :=
'Fuel Oil' 1 . . 568.165
'Fuel Oil' 2 . . 4878.24
'Fuel Oil' 3 . . 1304.34
'Fuel Oil' 4 . . 60.0276
'Fuel Oil' 5 . . 2.27374e-12
'Fuel Oil' 6 . . 118.093
'Fuel Oil' 7 . . 489.94
'Fuel Oil' 8 . . 1714.39
'Fuel Oil' 9 . . 2468.6
'Fuel Oil' 10 . . 1073.29
'Fuel Oil' 11 . . 100.265
'Fuel Oil' 12 . . -1.77351e-11
'Jet Fuel' 1 . 0 9.09495e-13
'Jet Fuel' 2 . 0 6098.4
'Jet Fuel' 3 . 0 -9.09495e-13
'Jet Fuel' 4 . 0 -5.45697e-12
'Jet Fuel' 5 . 0 1.27329e-11
'Jet Fuel' 6 . 0 -1.09139e-11
'Jet Fuel' 7 . 0 -1.00044e-11
'Jet Fuel' 8 . 0 -4.54747e-12
'Jet Fuel' 9 . 0 -9.09495e-13
'Jet Fuel' 10 . 0 1.00044e-11
'Jet Fuel' 11 . 0 9.09495e-12
'Jet Fuel' 12 . 0 1.00044e-11
'Premium Gasoline' 1 -3.09633 . 2.27374e-12
'Premium Gasoline' 2 -3.11884 . 3912.48
'Premium Gasoline' 3 0 . 3.63798e-12
'Premium Gasoline' 4 -3.02616 . 2095.6
'Premium Gasoline' 5 -3.06752 . 5197.88
'Premium Gasoline' 6 -3.13694 . 3530.89
'Premium Gasoline' 7 -3.20608 . 1589.64
'Premium Gasoline' 8 -3.21007 . -1.00044e-11
'Premium Gasoline' 9 -3.2059 . -2.09184e-11
'Premium Gasoline' 10 -2.98411 . -5.45697e-12
'Premium Gasoline' 11 -2.99578 . -7.7307e-12
'Premium Gasoline' 12 -2.96132 . -4.54747e-12
'Regular Gasoline' 1 . . -1.81899e-12
'Regular Gasoline' 2 . . 7330.4
'Regular Gasoline' 3 . . -3.63798e-12
'Regular Gasoline' 4 . . -2.72848e-12
'Regular Gasoline' 5 . . 1366.98
'Regular Gasoline' 6 . . 682.848
'Regular Gasoline' 7 . . -1.81899e-11
'Regular Gasoline' 9 . . 1.27329e-11
'Regular Gasoline' 10 . . 2.18279e-11
'Regular Gasoline' 11 . . 3.45608e-11
'Regular Gasoline' 12 . . 1.81899e-11
;
Demand ['Fuel Oil',Station1,*,*]
: 1 2 3 4 5 6 :=
1 0 3800 0 0 0 0
2 0 3610 0 0 0 0
3 0 3610 0 0 0 0
4 0 3610 0 0 0 0
5 0 2755 0 0 0 0
6 0 2375 0 -3.57307e-27 0 0
7 0 2375 0 0 0 0
8 0 2660 0 0 0 0
9 0 3135 0 0 0 0
10 0 3230 0 0 0 0
11 0 3325 0 0 0 0
12 3168 0 0 0 0 0
['Jet Fuel',Station1,*,*]
: 1 2 3 4 5 6 :=
1 6160 0 0 0 0 0
2 6160 0 0 0 0 0
3 6160 0 0 -1.64424e-27 0 0
4 7920 0 0 0 0 0
5 10560 -5.77581e-27 0 0 0 0
6 8800 0 0 0 0 0
7 7920 0 0 0 -3.91569e-27 0
8 7040 0 0 -2.69196e-27 0 0
9 7040 0 0 0 0 0
10 7920 0 0 0 0 0
11 6160 0 0 -1.38802e-26 0 0
12 6160 0 0 2.44485e-27 0 0
['Lube Oil',Station1,*,*]
: 1 2 3 4 5 6 :=
['Premium Gasoline',Station1,*,*]
: 1 2 3 4 5 6 :=
1 3960 0 0 0 0 0
2 3960 0 0 0 0 0
3 3960 0 0 0 0 0
4 3960 0 0 0 0 0
5 4400 0 0 0 0 0
6 6160 0 0 0 0 0
7 6600 0 0 0 0 0
8 6160 0 0 0 0 0
9 5280 0 0 0 0 0
10 4400 0 0 0 0 0
11 3960 0 0 0 0 0
12 4400 0 0 0 0 -7.48227e-26
['Regular Gasoline',Station1,*,*]
: 1 2 3 4 5 6 :=
1 7480 0 0 0 0 0
2 7480 0 0 0 0 0
3 7480 -1.66463e-27 0 0 0 0
4 7744 0 0 0 3.5795e-27 0
5 8096 0 0 0 0 0
6 11880 0 0 0 0 0
7 12284.7 0 0 0 0 0
8 11377.6 0 0 0 0 0
9 10517.4 0 0 0 0 0
10 8800 0 0 0 5.71403e-27 0
11 7920 0 2.83097e-27 0 0 0
12 8800 0 0 0 0 -3.11251e-27
;
: Loan_In Loan_Out :=
I 2 194710 0
I 3 0 195765
;
CashFlow [*] :=
1 232094 4 78728.1 7 615940 10 350867
2 -2232090 5 -433610 8 386024 11 331837
3 2481690 6 535397 9 197119 12 240251
;
Waste_Pollutant [*,*] (tr)
: Hydrocarbon 'Sulfur dioxide' :=
1 269077 385681
2 511614 734160
4 250804 371779
5 324924 480952
6 248116 361996
7 267436 392203
8 267234 392757
9 276422 408244
10 219856 322741
11 200985 295620
12 228633 337255
;
Octane number for products: 1 Fuel Oil 0.00
Octane number for products: 2 Fuel Oil 0.00
Octane number for products: 3 Fuel Oil 0.00
Octane number for products: 4 Fuel Oil 0.00
Octane number for products: 5 Fuel Oil 0.00
Octane number for products: 6 Fuel Oil 0.00
Octane number for products: 7 Fuel Oil 0.00
Octane number for products: 8 Fuel Oil 0.00
Octane number for products: 9 Fuel Oil 0.00
Octane number for products: 10 Fuel Oil 0.00
Octane number for products: 11 Fuel Oil 0.00
Octane number for products: 12 Fuel Oil 0.00
Octane number for products: 1 Regular Gasoline 83.99
Octane number for products: 2 Regular Gasoline 83.99
Octane number for products: 3 Regular Gasoline 0.00
Octane number for products: 4 Regular Gasoline 83.98
Octane number for products: 5 Regular Gasoline 83.98
Octane number for products: 6 Regular Gasoline 84.00
Octane number for products: 7 Regular Gasoline 83.99
Octane number for products: 8 Regular Gasoline 83.99
Octane number for products: 9 Regular Gasoline 84.00
Octane number for products: 10 Regular Gasoline 83.99
Octane number for products: 11 Regular Gasoline 84.00
Octane number for products: 12 Regular Gasoline 83.99
Octane number for products: 1 Lube Oil 0.00
Octane number for products: 2 Lube Oil 0.00
Octane number for products: 3 Lube Oil 0.00
Octane number for products: 4 Lube Oil 0.00
Octane number for products: 5 Lube Oil 0.00
Octane number for products: 6 Lube Oil 0.00
Octane number for products: 7 Lube Oil 0.00
Octane number for products: 8 Lube Oil 0.00
Octane number for products: 9 Lube Oil 0.00
Octane number for products: 10 Lube Oil 0.00
Octane number for products: 11 Lube Oil 0.00
Octane number for products: 12 Lube Oil 0.00
Octane number for products: 1 Premium Gasoline 93.95
Octane number for products: 2 Premium Gasoline 93.98
Octane number for products: 3 Premium Gasoline 0.00
Octane number for products: 4 Premium Gasoline 93.98
Octane number for products: 5 Premium Gasoline 93.99
Octane number for products: 6 Premium Gasoline 93.94
Octane number for products: 7 Premium Gasoline 93.96
Octane number for products: 8 Premium Gasoline 93.96
Octane number for products: 9 Premium Gasoline 93.95
Octane number for products: 10 Premium Gasoline 93.96
Octane number for products: 11 Premium Gasoline 93.93
Octane number for products: 12 Premium Gasoline 93.96
Octane number for products: 1 Jet Fuel 0.00
Octane number for products: 2 Jet Fuel 0.00
Octane number for products: 3 Jet Fuel 0.00
Octane number for products: 4 Jet Fuel 0.00
Octane number for products: 5 Jet Fuel 0.00
Octane number for products: 6 Jet Fuel 0.00
Octane number for products: 7 Jet Fuel 0.00
Octane number for products: 8 Jet Fuel 0.00
Octane number for products: 9 Jet Fuel 0.00
Octane number for products: 10 Jet Fuel 0.00
Octane number for products: 11 Jet Fuel 0.00
Octane number for products: 12 Jet Fuel 0.00
Vapor pressure limits of product Jet Fuel: 1 Jet Fuel 0.33
Vapor pressure limits of product Jet Fuel: 2 Jet Fuel 0.33
Vapor pressure limits of product Jet Fuel: 3 Jet Fuel 0.00
Vapor pressure limits of product Jet Fuel: 4 Jet Fuel 0.38
Vapor pressure limits of product Jet Fuel: 5 Jet Fuel 0.41
Vapor pressure limits of product Jet Fuel: 6 Jet Fuel 0.39
Vapor pressure limits of product Jet Fuel: 7 Jet Fuel 0.43
Vapor pressure limits of product Jet Fuel: 8 Jet Fuel 0.34
Vapor pressure limits of product Jet Fuel: 9 Jet Fuel 0.34
Vapor pressure limits of product Jet Fuel: 10 Jet Fuel 0.41
Vapor pressure limits of product Jet Fuel: 11 Jet Fuel 0.37
Vapor pressure limits of product Jet Fuel: 12 Jet Fuel 0.35
Premium / Regular percentage: 1 0.53
Premium / Regular percentage: 2 0.53
Premium / Regular percentage: 3 0.00
Premium / Regular percentage: 4 0.79
Premium / Regular percentage: 5 0.79
Premium / Regular percentage: 6 0.40
Premium / Regular percentage: 7 0.40
Premium / Regular percentage: 8 0.40
Premium / Regular percentage: 9 0.50
Premium / Regular percentage: 10 0.50
Premium / Regular percentage: 11 0.50
Premium / Regular percentage: 12 0.50
Production Fuel Oil ratio: 1 Cracked Oil 4.00
Production Fuel Oil ratio: 2 Cracked Oil 4.00
Production Fuel Oil ratio: 3 Cracked Oil 0.00
Production Fuel Oil ratio: 4 Cracked Oil 4.00
Production Fuel Oil ratio: 5 Cracked Oil 4.00
Production Fuel Oil ratio: 6 Cracked Oil 4.00
Production Fuel Oil ratio: 7 Cracked Oil 4.00
Production Fuel Oil ratio: 8 Cracked Oil 4.00
Production Fuel Oil ratio: 9 Cracked Oil 4.00
Production Fuel Oil ratio: 10 Cracked Oil 4.00
Production Fuel Oil ratio: 11 Cracked Oil 4.00
Production Fuel Oil ratio: 12 Cracked Oil 4.00
Production Fuel Oil ratio: 1 Heavy Oil 3.00
Production Fuel Oil ratio: 2 Heavy Oil 3.00
Production Fuel Oil ratio: 3 Heavy Oil 0.00
Production Fuel Oil ratio: 4 Heavy Oil 3.00
Production Fuel Oil ratio: 5 Heavy Oil 3.00
Production Fuel Oil ratio: 6 Heavy Oil 3.00
Production Fuel Oil ratio: 7 Heavy Oil 3.00
Production Fuel Oil ratio: 8 Heavy Oil 3.00
Production Fuel Oil ratio: 9 Heavy Oil 3.00
Production Fuel Oil ratio: 10 Heavy Oil 3.00
Production Fuel Oil ratio: 11 Heavy Oil 3.00
Production Fuel Oil ratio: 12 Heavy Oil 3.00
Production Fuel Oil ratio: 1 Light Oil 10.00
Production Fuel Oil ratio: 2 Light Oil 10.00
Production Fuel Oil ratio: 3 Light Oil 0.00
Production Fuel Oil ratio: 4 Light Oil 10.00
Production Fuel Oil ratio: 5 Light Oil 10.00
Production Fuel Oil ratio: 6 Light Oil 10.00
Production Fuel Oil ratio: 7 Light Oil 10.00
Production Fuel Oil ratio: 8 Light Oil 10.00
Production Fuel Oil ratio: 9 Light Oil 10.00
Production Fuel Oil ratio: 10 Light Oil 10.00
Production Fuel Oil ratio: 11 Light Oil 10.00
Production Fuel Oil ratio: 12 Light Oil 10.00
Production Fuel Oil ratio: 1 Residuum 1.00
Production Fuel Oil ratio: 2 Residuum 1.00
Production Fuel Oil ratio: 3 Residuum 0.00
Production Fuel Oil ratio: 4 Residuum 1.00
Production Fuel Oil ratio: 5 Residuum 1.00
Production Fuel Oil ratio: 6 Residuum 1.00
Production Fuel Oil ratio: 7 Residuum 1.00
Production Fuel Oil ratio: 8 Residuum 1.00
Production Fuel Oil ratio: 9 Residuum 1.00
Production Fuel Oil ratio: 10 Residuum 1.00
Production Fuel Oil ratio: 11 Residuum 1.00
Production Fuel Oil ratio: 12 Residuum 1.00
7. Retrieve solution and export it to a *.xlsx file#
Write the data to an *.xlsx file.
! pip install openpyxl
amplvar = dict()
# Create an ExcelWriter object for saving DataFrames to an Excel file at the specified path
with pd.ExcelWriter("oil_refyning.xlsx") as writer:
# Generate a list of all variable names from the AMPL model
list_of_ampl_variables = [item[0] for item in ampl.get_variables()]
# Iterate over each variable name in the list
for key_ampl in list_of_ampl_variables:
# Skip certain variables that are not to be processed (these variables won't be included in the output)
if key_ampl not in [
"X",
"Cracking_X",
"Distill_X",
"Lubricating_X",
"Reform_X",
]:
# Convert the AMPL variable data to a pandas DataFrame
df = ampl.var[key_ampl].to_pandas()
# Filter the DataFrame to include only rows where the variable's value is greater than a small threshold (10^-5)
filtered_df = df[df[f"{key_ampl}.val"] > 10e-5]
# Save the filtered DataFrame to the corresponding sheet in the Excel file
if not filtered_df.empty: # Ensure that only non-empty DataFrames are saved
filtered_df.to_excel(writer, sheet_name=key_ampl, index=True)
# Save the filtered DataFrame to a dictionary
# amplvar[key_ampl] = filtered_df
8. Retrieve solution and export it to a Google Sheets document#
Write the data to an Google Sheets document.
! pip install google-auth google-auth-oauthlib gspread
import gspread # https://docs.gspread.org/en/v6.0.0/user-guide.html
from google.oauth2.service_account import Credentials
scopes = ["https://www.googleapis.com/auth/spreadsheets"]
credentials = Credentials.from_service_account_file("credentials.json", scopes=scopes)
client = gspread.authorize(credentials) # Use gspread to open the Google Sheet
spreadsheet = client.open_by_key(
"15R3QuyUFN_oVztI_P4lM9C5mjsYC7ZKUO-BogCdt81s"
) # Open the Google Sheets document by name
list_of_ampl_variables = [
item[0] for item in ampl.get_variables()
] # Retrieve a list of AMPL variables from the AMPL environment
variables_to_exclude = [
"X",
"Cracking_X",
"Distill_X",
"Lubricating_X",
"Reform_X",
] # List of variables to exclude from the export
filtered_ampl_variables = [
var for var in list_of_ampl_variables if var not in variables_to_exclude
]
for key_ampl in filtered_ampl_variables: # Iterate through each AMPL variable
ampl_dict = (
ampl.getVariable(key_ampl).getValues().toDict()
) # Retrieve AMPL variable values and convert them to a dictionary
filtered_dict = { # Filter the dictionary to exclude certain variables and include only values greater than 0.0001
key: value for key, value in ampl_dict.items() if value > 0.0001
}
# if filtered_dict: # Only process further if there's data to be exported
if key_ampl not in [
sheet.title for sheet in spreadsheet.worksheets()
]: # Check if the current variable's name is not already a sheet in the spreadsheet
new_sheet_name = (
f"{key_ampl}" # Create a new sheet with a unique name based on the variable
)
spreadsheet.add_worksheet(
title=new_sheet_name, rows=100, cols=20
) # Add a new worksheet to the spreadsheet with a default size of 100 rows and 20 columns
sheet = spreadsheet.worksheet(
key_ampl
) # Get the worksheet object corresponding to the current variable
sheet.clear() # Clear the existing data in the sheet
first_key = next(
iter(filtered_dict.keys()), None
) # Get the first key to determine the data structure
if isinstance(
first_key, tuple
): # Check if the first key is a tuple, indicating multi-dimensional data
number_of_columns = len(first_key)
indices = [f"index{i}" for i in range(number_of_columns)]
data = [] # Prepare data for DataFrame
for key, value in filtered_dict.items():
data.append(
[str(k) for k in key] + [value]
) # Convert each part of the key tuple to a string and append the value
columns = indices + [
key_ampl + ".val"
] # Define column names including value column
else:
# Handle one-dimensional data
indices = [""] # Single index column
data = [
[str(key), value] for key, value in filtered_dict.items()
] # Convert key to string and pair it with the value
columns = indices + [
key_ampl + ".val"
] # Define column names including value column
df = pd.DataFrame(
data, columns=columns
) # Create a DataFrame from the prepared data
data_list = [
df.columns.tolist()
] + df.values.tolist() # Convert DataFrame to list of lists
sheet.update(
data_list, "A1"
) # Update the Google Sheet with the prepared data starting from cell A1
Load Data into the Power BI Report from Google Sheets#
To ensure we have the most up-to-date information, we’ll refresh the data in the Oil Refinery report. Once the data is updated, the latest model solution will be visualized on the “Result” page, providing a clear and accurate reflection of the current outcomes.